
AI 101 Terminology
The terminology of AI
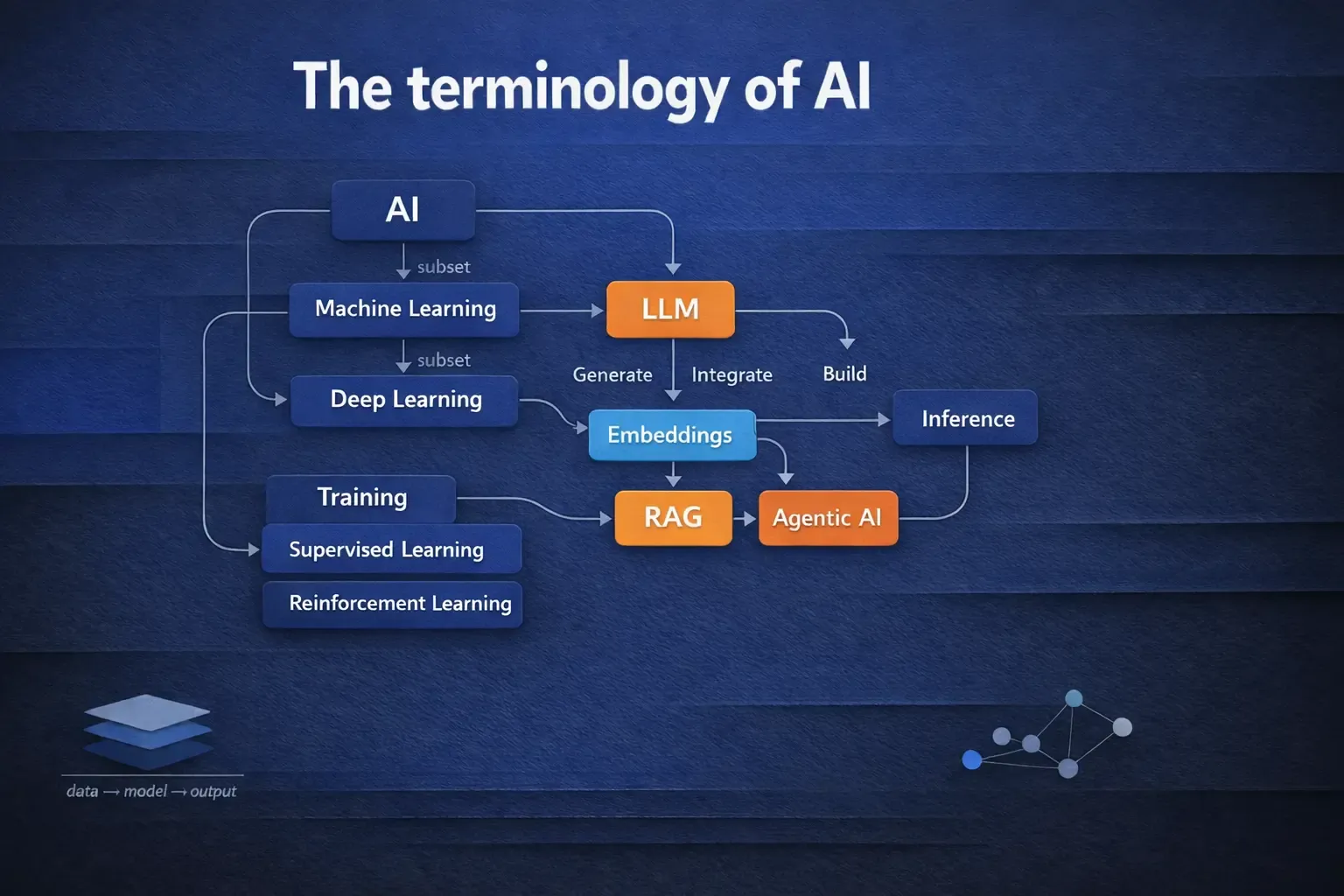
As AI becomes more mainstream, more terms are being added into the mix, probably every single week. Generative AI, Agentic AI, RAG, LLMs, SLMs, Reinforcement Learning, Transformers, Prompt Engineering, Embeddings ….. It can become confusing as some of these terms also overlap.
In this blog, we define and categorize some of the commonly used terms, and more importantly, highlight the differences between those terms.
AI, and its various Phrases
Let’s begin with AI - As it is common knowledge, it stands for Artificial Intelligence. AI is a broad umbrella term for any computer software or a system that behaves such that it mimics human intelligence. During the dusk time, if the light intensity in the room decreases, the “AI lamp” would know that and switch on the bulb for you, just like a human would switch on the light. The term AI is used both in business and academia.
AI is built up of models. They are mathematical processes or algorithms that are generated usually out of training data (we will come to training data later). Just how software releases have versions, model releases are also multiple, and they also have versions. It is simply a system that takes data as an input and produces a mechanism that can turn into an output.
There are classes of models today that are able to generate new content (text, audio, images, video, computer programs) - these are called Generative AI models. The commercial offerings of ChatGPT, Claude, and Gemini started as text-based Generative AI models. Since they used to just process and provide generative text, they were also called Chat Bots. Today they have expanded to include images, videos, and code, too.
Also, another popular term nowadays in the industry is Agentic AI. It is a system built on AI that takes some autonomous actions on its own. Usually, these autonomous actions are oriented towards a particular goal, and they might involve some multi-step reasoning element. A good example of this is a project called Auto-GPT. It can do some of the seemingly routine and mundane tasks for you when set up right. I have set it up to monitor “interesting” publications in the AI that get published in some of the pre-chosen journals/conferences. Nowadays (in 2025), many of these “agentic” capabilities are already offered within the commercial offerings of the Generative AI models.
Dichotomy of AI based on applications
AI today is used for many different problem-solving applications:
- Anything that involves solving a problem mimicking the visual processing and interpretation is called Computer Vision-based AI. Today’s Computer Vision models can perform object detection, recognition, and tracking, as well as generate new images/videos.
- There are audio models too: Automatic Speech Recognition (ASR) is able to interpret speech and convert it into text or some commands. Siri and Alexa use ASR of some kind. There are text-to-speech (TTS) models that convert the written text into artificial speech, with certain accents and nuances.
- NLP (Natural Language Processing) is also where AI excels today. This is understanding human language (and generating it). There are language translation models, too.
- Robotics is where AI is put into action in a physical space.
Deep Learning, Machine Learning, Data Science
We also hear phrases such as Deep Learning, Machine Learning, Data Science - all of these streams are related to AI.\

Machine Learning refers to the class of AI models that are learning from the data they are provided. The data that is used for building the models is called Training Data. The data on which the models are tested are called Test Data or Test sets.
The term Supervised Learning refers to the machine learning methods that are trained on labeled data. Labeled data here means some target values that the model is trying to learn. For example, in a character recognition problem, the image of a character is the input of training data, the label is the actual character - say 6 or A. To solve this problem, a lot of input images are collected, along with their corresponding target labels, and the machine learning model attempts to associate the image with a corresponding label. Unsupervised Learning is where there is no fixed label; it is used to find some hidden patterns out of the dataset, OR tries to group similar things together (Clustering). There are multiple different types of Machine Learning models available, such as Decision Trees, Support Vector Machines (SVMs), Linear Discriminant Analysis (LDA), Artificial Neural Networks (ANNs) (also very often just called as Neural Networks).
ANNs are a particularly important class of machine learning models because they have paved the way for Deep Learning. They were inspired by how the brain neurons work (and the technology has deviated quite some way away from it :) )

The diagram above is the simplest form of a neural network. Each circle represents a node of a neural network, and each link/edge between the nodes is called a weight. ANNs are made up of layers. On one side, there is an Input Layer, and on the other side, there is an Output Layer. The intermediate layers are called Hidden Layers. There is only one hidden layer shown in the diagram; it is more common to have multiple hidden layers in an ANN.
The input layers are the layers where you feed in the inputs or features (for example: pixels or a group of pixels of an input image; words or text tokens of a paragraph/book; and so on). The hidden layers are used for internal representation of the concepts, and the output layer consists of the targeted outputs that we desire. We will cover ANNs in more detail in another blog in this series later.
Deep Learning refers to the class of Neural Networks that are having many many hidden layers. Strictly technically, any ANN having more than one hidden layer is deep, but practically the ANN models that have hundreds or thousands of hidden layers is considered a Deep Neural Network. In the 2010s, these Deep Neural Network models started breaking the benchmarks in various known AI problems. While other (non-Deep) Machine Learning based models still have their role in the industry, the majority of today’s AI is powered by Deep Learning models.
Now, where does Data Science fit in? Data Science is considered a broader field overlapping with AI, where the focus is on the data, not necessarily on the models. The entire process of collecting, cleaning, processing, visualizing, analyzing, interpreting, and even building models out of the data is called Data Science. Roughly speaking, the relationship between Data Science and AI is like the Venn diagram below.
 One important type of Machine Learning is Reinforcement learning, where the AI agent learns to make decisions based on the inputs and interactions with an environment, receiving some sort of reward or penalties along the way to course-correct its strategy. For example, a robot finds its own way in a maze, capturing inputs as it collides with walls along the way. It’s a fairly old type of machine learning technique, gaining resurgence again, coupled with Deep Learning. This Deep Reinforcement Learning is a very potent force, exhibiting correct decision-making even in uncertain situations. We will learn more about it in one of the blogs later.
One important type of Machine Learning is Reinforcement learning, where the AI agent learns to make decisions based on the inputs and interactions with an environment, receiving some sort of reward or penalties along the way to course-correct its strategy. For example, a robot finds its own way in a maze, capturing inputs as it collides with walls along the way. It’s a fairly old type of machine learning technique, gaining resurgence again, coupled with Deep Learning. This Deep Reinforcement Learning is a very potent force, exhibiting correct decision-making even in uncertain situations. We will learn more about it in one of the blogs later.
Training and inference of models
All Machine Learning models have two main phases. Training and Inference. Training is the process where the model attempts to learn from the data (usually labeled data) it’s provided with, and it estimates some parameters of the model. Parameters are like knobs of a machine, some tunable things that configure the machine, and training is the process to tune them right for the task at hand.
As a very simplistic example, you might want to make a model to classify between the images of “apple” and “banana”. You will need to have a bunch of apple images labeled as “apple’, and a bunch of images of bananas labeled as “banana”. The model training process starts with randomly chosen parameters. Every time you show an image to the model, you are asking the model to predict the label. Every incorrectly predicted output makes some systematic changes in the parameters. After many iterations of this process, you might settle on a set of parameters that classifies the apple images and the banana images with fairly high accuracy. That’s when you stop the training process. For the simplistic banana example, to classify it properly, the parameters pertaining to the color of the object or the length of the object , may have a higher value.
Inference is the process by which these trained models are used to make predictions on new, unseen data. While training can be a one-time (or limited-time) running activity, inference is a far more recurring activity.
The size of the models
For Deep Learning models, the parameters you are estimating during the training phases are the “weights” of the neural network as described in the earlier section. As time progresses, larger models (with more parameters) come into existence. When the models reached around the size of a billion parameters/weights in 2022-2023, the term Large Language Models (LLMs) was widely adopted. The number of parameters in today’s deep learning models is a few billion. The latest version of ChatGPT is estimated to have close to 2 trillion parameters! Training a model of this size is an extremely costly proposition, estimated to have 1.5-$2.5 billion for a full training. This is also why only a handful of companies today are able to afford building such models.
Models of this size are typically trained on a lot of diverse data, and also asked to perform on a lot of possible tasks all at once. Because of that, they are also called Foundational Models.
Other popular concepts of the LLM ecosystem
For time efficiency, the training and inference of the LLM models happen on specialized computer chips called GPUs (Graphical Processing Units) - GPUs have thousands of smaller, parallel cores that can handle multiple small calculations in parallel - just the perfect thing that the Neural Nets need!
Depending on the usage, it has also become very popular to combine an LLM with some additional knowledge base to ensure the models are able to answer based on some domain-specific (or some recent) data that they might not have been trained on! The process with which such an augmentation is done is called Retrieval-Augmented Generation (RAG).
One other way one can use a pre-trained LLM to work on specific domain-specific data or tasks is to use a process called fine-tuning. It modifies some number of weights of the LLMs to ensure that the modified LLMs are able to work better on the domain-specific data. This does require access to the original LLM weights. Almost all of the commercial offerings of LLMs are not provide weights publicly. Luckily, though, there are some open LLMs (and datasets) to use. This resource has a good summary of open LLMs as of now.
An Embedding is a high-dimensional vector form that is generated by the Deep Learning Models, referring to a real-world entity. They can be applied to text, audio, images, and video, too. The embeddings can be Multimodal too, supporting more than one mode of data at once. The embeddings are supposed to preserve the semantic meaning and its relationships with the data. I.e., an embedding of a “cat” and a “mouse” is closer to each other than a “cat” and a “desktop” (but embedding of a “mouse” and a “desktop” may be closer too!).
Obviously, it is an art and a fair bit of engineering to train the LLMs; it’s also somewhat of an art and engineering in how you ask the questions to LLMs. In a complex workflow involving LLMs, one might need to provide very specific instructions - often along with examples, which is called prompts. There are multiple prompting (also known as prompt-engineering) techniques that we will discuss in another blog later.
Conclusion - with a final term
The AI models have become Generative and super-expressive today, but whether they will achieve AGI (Artificial General Intelligence) is a hot topic. The AI models today are able to respond to conversation and even generate content in a seemingly intelligent fashion, but under the hood, they require swathes of training data. They seem to lack instant learning, and specifically, they seem to lack the conceptual and reasoning-based underpinnings based learning that can be applied across a wide range of tasks naturally. It is safe to say today these models have not reached at that level, someday they will, probably surpassing human reasoning too! That would be both exciting and scary at the same time!



