Reinforcement Learning : A Beginner-Friendly Guide
Reinforcement Learning : A Beginner-Friendly Guide
Artificial intelligence has made great strides, Reinforcement Learning (RL) is a particular sub-branch with its ability to learn through interactions, like humans. From self-driving cars to breakthrough scientific discoveries such as AlphaFold, reinforcement learning has quietly powered some of the biggest technological achievements of our time.
Consider a few real-world examples: • Robotics: Robots learning to grasp objects they’ve never seen before, or helicopters flying through unknown terrains, simply through trial and error. • Gaming: AI agents beating world champions in Go, Chess, and complex video games like Dota2. • Recommendations: Systems that optimize long-term engagement rather than just immediate clicks.
These achievements highlight RL’s ability to handle problems where traditional supervised learning techniques fall short. particularly when decisions have long-term consequences, sequential decision making, and uncertain environments.
This blog explores the basics of reinforcement learning, its core components, commonly used algorithms, practical tools, applications, and its limitations.
What is Reinforcement Learning?
Reinforcement learning is a specific type of machine learning. There is an entity called RL Agent that tries to make decisions by interacting with the environment that maximizes long-term rewards. Unlike traditional ML where the data is labeled, in RL, the data is generated by lot of simulations and explorations.
Components of Reinforcement Learning (RL)
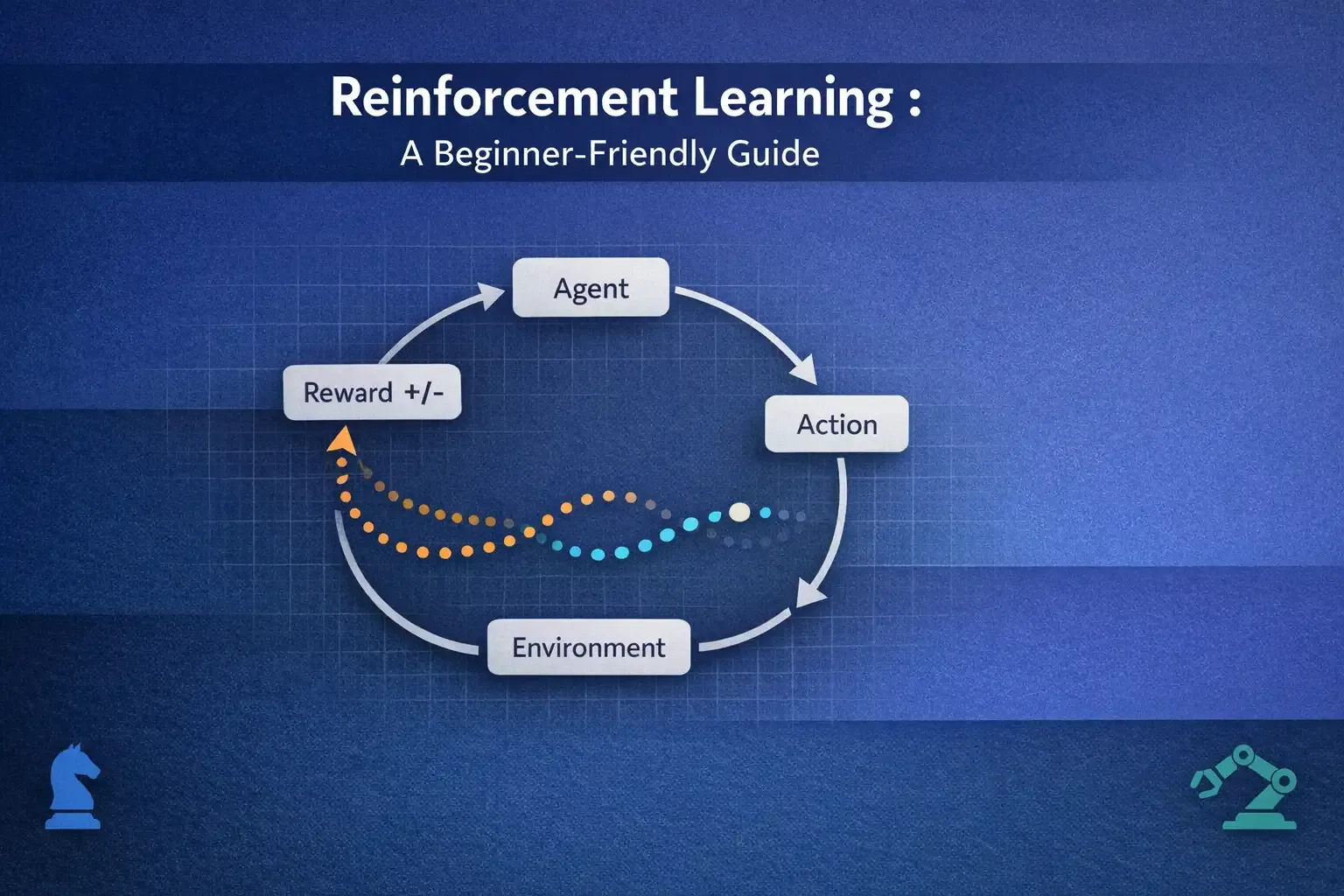
RL systems are often described using Markov Decision Processes (MDPs). The main components are:
- Agent: It is a system having State, Policy, and Action, and it interacts with the Environment.
- Environment: It is a system that receives action from an agent, changes its state. The environment also returns the feedback.
- State: A representation of the environment that captures all the fundamental information succinctly.
- Action: Set of possible alternatives that an agent can choose
- Reward: positive or negative Feedback
- Policy: The agent’s strategy.
- Value Function: Estimates long-term reward expectations.
The RL algorithms can be considered in two classes. on-policy algorithms learn as they go, on the policy that they may be executing. It is like a piano master improvising on the cue of the audience response. The off-policy is learning through others’ experiences or past experiences. The Off-policy algorithms have benefit of lot more sampling data usually, but they may not have the most relevant data necessarily.
All RL systems make good use of “exploration” vs “exploitation” tradeoff. Exploration means taking some new / less-known action (in the hope of possible likely reward). Exploitation is choosing the best-known action based on the available information that the agent has.

Popular Reinforcement Learning Algorithms
1. SARSA
An on-policy algorithm that updates values based on actions the agent actually takes.
2. Q-Learning
An off-policy algorithm that learns an optimal action-value function independent of current behavior.
3. Monte Carlo Methods
Learn from complete episodes by averaging returns.
4. TD-Lambda
A hybrid of temporal difference learning and Monte Carlo, balancing bias and variance.
5. Deep Q Networks (DQN)
Combines Q-learning with deep neural networks to master environments like Atari.
6. Policy Gradient Methods
Learn policies directly, excellent for robotics and continuous action spaces.
Applications of Reinforcement Learning
- Games & Simulation: Chess, Go, Atari, StarCraft, Dota 2.
- Scientific Research: AlphaFold for protein structure prediction.
- Autonomous Driving: Lane keeping, obstacle avoidance, decision-making.
- Robotics: Navigation, manipulation, locomotion.
- RLHF: Powering modern LLM alignment.
- Industry: Inventory optimization, resource allocation, energy systems.
Limitations of Reinforcement Learning
- Need of lot of data: Requires millions of interactions.
- Exploration Challenges: Balancing exploration and exploitation.
- Training Instability: Sensitive to hyperparameters.
- Reward Engineering Issues: Poorly crafted rewards cause unexpected behaviors.
- Weak Generalization: Agents may fail under new conditions.
Practical Examples Using RL Tools
OpenAI Gymnasium
A toolkit providing environments like CartPole, MountainCar, LunarLander, and Atari.
Stable Baselines3
A library offering ready-to-use RL algorithms.
import gymnasium as gym
from stable_baselines3 import PPO
env = gym.make("CartPole-v1")
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000)
obs, _ = env.reset()
for _ in range(500):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
obs, _ = env.reset()This code trains a PPO (Proximal Policy Optimization) RL agent on the Cartpole-v1 environment using Stable-Baseline-3. The agent learns a policy over 10000 steps interacting with the environment. Later, the policy is evaluated for 500 steps for its perfomance by selecting actions and observing rewards.
Conclusion
Reinforcement learning focuses on learning through interactions with the environment with consistent sequential decision making. effects. While it remains a challenging field with limitations, modern tools and research progress are making RL increasingly accessible for developers, researchers, and enthusiasts.
The future of RL is promising, with the advent of more compute being accessible. The combination of Deep Learning and RL is very potent, giving rise to Deep Neural Networks.